Akka Cluster Load Balancing
Example producer consumer(s) application that shows how Akka routing can be used to balance the load of the nodes in an Akka Cluster.
In the example application below, an Akka Cluster with the single producer and multiple consumer nodes is created. The producer sends messages to consumers via routing strategy. If messages are routed well, the load can be balanced across all consumer nodes.
Akka has multiple routing strategies implemented already like the random strategy that will randomly select one of the consumer nodes for each message, or the round robin strategy that will send messages to each consumer node with roughly equal frequency. It's also possible to implement a custom strategy. On top of that, there is the Cluster Metrics Extension which has the adaptive load balancing strategy that will select consumer nodes based on the cluster metrics data, in our case, mostly based on the remaining heap capacity of each consumer node.
Setup
- 1 producer node is started. It contains 2 actors: the producer actor that sends 10 messages per second and the cluster listener actor that collects and logs average heap usage of each consumer node.
- 4 consumer nodes are started. Each node contains 1 consumer actor. All consumers can together process 11 messages per second. However, each of them processes messages at different rate.
- Running on java version 1.8.0_31.
- Each node in the cluster is started on the same computer but on different jvm with settings -Xmx256m -XX:NewSize=128m -XX:MaxNewSize=128m -XX:+UseConcMarkSweepGC -XX:+CMSIncrementalMode.
- I am using default Akka Cluster metrics settings.
- Message size is around 1 MB.
Above description of producer and consumer nodes is illustrated on the diagram below:

To make sure that consumer nodes will not crash with Out Of Memory errors, the adaptive load balancing strategy must be used, so that most messages will be send to C1 and C2, less to C3 and the least to C4. If all consumers processed messages with the same rate, the round robin or even the random routing logic would have probably worked better than the adaptive load balancing strategy. For the sake of the comparison, results for both the adaptive and the round robin logic are presented later in this post.
Code
Producer actor.
class Producer(val sendIntervalMillis: Int, val dataArraySize: Int)
extends Actor {
import context.dispatcher
context.system.scheduler.schedule(
1.second, sendIntervalMillis.millis, self, "send")
val consumerRouter =
context.actorOf(FromConfig.props(), name = "consumerRouter")
val data = Array.range(0, dataArraySize)
def receive: Receive = {
case "send" => consumerRouter ! data
}
}Consumer router configuration.
akka {
actor {
provider = "akka.cluster.ClusterActorRefProvider"
deployment {
/producer/consumerRouter = {
router = cluster-metrics-adaptive-group
metrics-selector = mix
nr-of-instances = 100
routees.paths = ["/user/consumer"]
cluster {
max-nr-of-instances-per-node = 1
enabled = on
use-role = consumer
allow-local-routees = off
}
}
}
}
}
Consumer actor.
class Consumer(val processingTimeMillis: Int)
extends Actor with UnboundedStash with ActorLogging {
import context.dispatcher
def receive: Receive = {
case data: Array[Int] => {
context.become(processing, discardOld = false)
context.system.scheduler.scheduleOnce(
processingTimeMillis.millis, self, "endProcessing")
}
}
def processing: Receive = {
case data: Array[Int] => stash()
case "endProcessing" => {
log.debug("endProcessing") // for unit test
unstashAll()
context.unbecome()
}
}
}Consumer actor simulates message processing for amount of time given by processingTimeMillis parameter. I am using UnboundedStash trait and Scheduler to simulate message processing without blocking the thread. Perhaps simple Thread.sleep(processingTimeMillis) would have been fine for this example.
When current context is set to the receive method, actor is ready to process the next data message. When it receives the next data message, it switches context to processing and schedules the "endProcessing" message to self. While in the processing context, newly received data messages are stashed for later processing. When "endProcessing" message is received, stashed data messages are unstashed, context is switched back to the receive method and consumer is once again ready to process the next data message.
Producer node is started with the ProducerApp and consumer node is started with the ConsumerApp. Node settings (hostname, port etc.) are configured trough java system properties. It is explained in the Running the application section of this post.
Complete source code is available at github.
Results
Charts below show average heap usage of consumer nodes during their lifespan. Zero memory usage represents a node that crashed with Out Of Memory error. C1 and C2 can process max. 4 messages per second, C3 max. 2 messages per second and C4 max. 1 message per second.
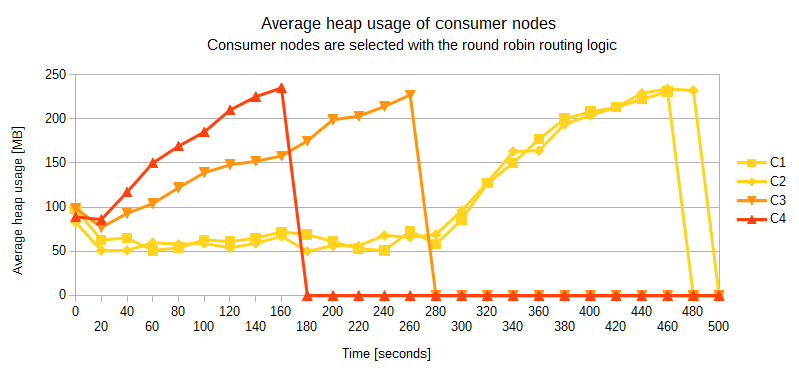
First, I have run the application with the round robin routing logic. As expected, all consumer nodes have quickly crashed with Out Of Memory errors. C4 has crashed first, after 160 seconds. It was followed by C3 100 seconds later. C1 and C2 have crashed last, surviving roughly the same amount of time, both around 500 seconds.
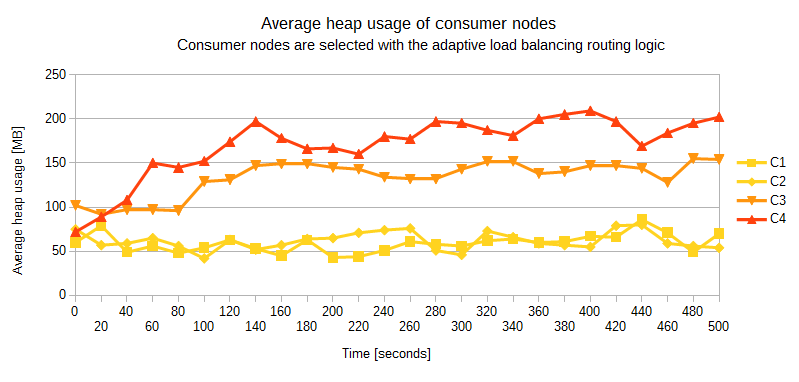
Next, I have run the application with the adaptive load balancing routing logic. I have limited results on the chart to 500 seconds. As seen below, load balancing router carefully chooses consumer nodes, keeping them safe from memory overflow. Also notice the inverse correlation of heap usage between the nodes.
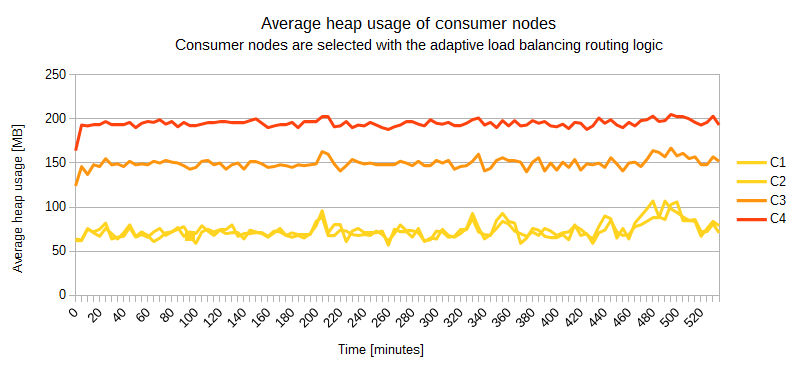
Lastly, I have run the application once again with the adaptive load balancing routing logic, but this time for around 9 hours. It looks like the adaptive load balancing logic works really well.
Next, I would like to start producer and consumer nodes not on single computer in multiple jvms, but on different computers in a network. It will be interesting to see how network latency will affect the adaptive load balancing routing logic. Most likely, it will still work really well. I will try to do that at work later next week, and if I do, I will write a follow-up post with the results.
Running the application
The easiest way to run the example application is to download akka-cluster-load-balancing-assembly-1.0.zip. It contains windows scripts that can run the application with the same setup as in this post. Customize the scripts to change:
- node hostname and port;
- seed node(s);
- producer message send interval;
- consumer message processing time;
- memory settings of node;
- metrics log interval (-Dproducer.metrics-interval-seconds);
- message size (-Dproducer.data-array-size), if message size is too big, make sure to also update akka maximum-frame-size, receive-buffer-size, send-buffer-size.
Alternatively fork the project from github, perhaps modify it and use sbt assembly command to build the jar. Then use included windows scripts to execute that jar. The scripts assume that the jar and the sigar directory are present in their directory.